220K real-time simulated pedestrians
The only way is up….. And we are above 200k real-time pedestrians on our 12-core, consumer PC! :-)
We have several metrics to measure our crowd simulation engine performance, and it is good to understand the difference. Why is it important, what are the benefits and how does it help us all?
We define the following three metrics. We use:
- Just raw engine performance (in C++): how many pedestrians can we simulate in real-time?
- Another raw engine performance (in C++): how faster than real-time can we simulate 20k people? Why 20k? Because that is an arbitrary size of a relevant area with people.
- And then the performance in our simulator, SimCrowds (in Unity3D), with 20k (fully 3D, animated) people: how much can we speed-up faster than real-time?
We have carried out the following experiments on three types of computers: a 2K€ laptop (8-core Dell XPS with NVIDIA GeForce GTX 1650), a 1.5K€ desktop consumer PC (12-core Ryzen 3900x with NVIDIA GeForce GTX 1080), and an 8K€ dream PC (64-core AMD ThreadRipper with NVIDIA GeForce GTX 2080ti). All timings also include the rendering times of the pedestrians.
In addition, we have set the internal engine parameters to unfavourable values for performance to stress-test the engine: after each period of 5 seconds, each pedestrians re-plans its path and takes updated crowd densities into account, and all pedestrians compute a similar short path to enforce a heavier payload on collision avoidance.
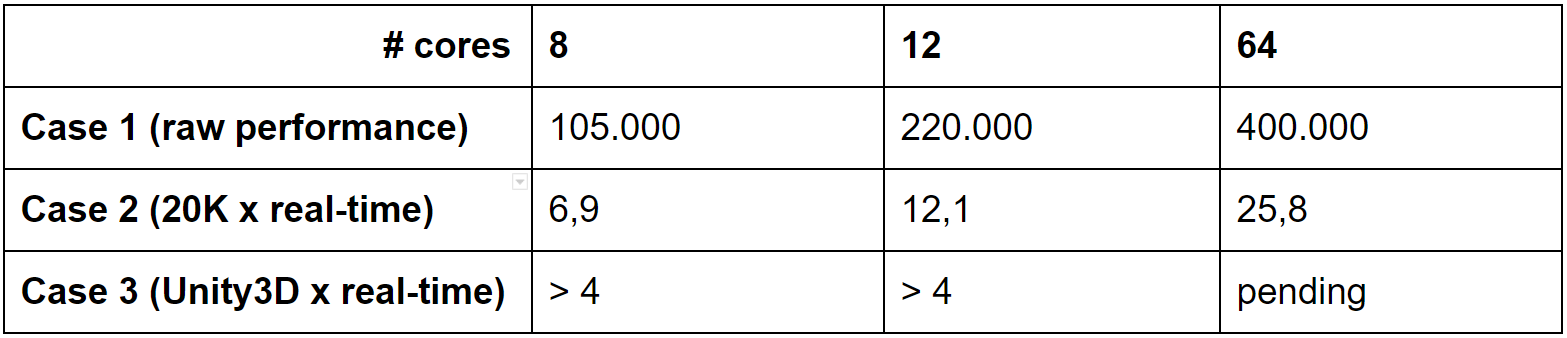
Parallelization is most of the time not evident, because the engine’s algorithms need to be suited for parallel execution. And when they can be made parallel, due to overhead in calculation, they are usually not linear. That is why we see that in case 2) the 20k times the speed-up is higher than the case 1). And since case 3) is a complete simulation application with real-time interaction, it is slower than case 2). Another result is that a low standard deviation of the frame times is achieved.
In our optimization process of the core engine, we can use parallelization on three levels: instruction level (SIMD), thread level (parallel tasks) and application level (asynchronous tasks). Our students from the Utrecht University master Game and Media Technology have been working on the thread and application level. Further optimizations in the engine and Unity application are still being made in their MSc projects.
We will keep you posted on our progress!
Read, like and share this post on our LinkedIn!